Python UUEncode Vulnerability


tl;dr Found a vuln in some old and mostly unused data format in python, spoke to Guido van Rossum (inventor of Python), and submitted a PR with a fix.
I had a look at the Python source code for and discovered a vulnerability in the UUEncode methods in Python. UUEncode is an old data format that is very rarely used anymore. It has been almost completely replaced by Base64.Multiple functions relating to uu encoding files in the python standard library (from 2.7 - 3.8) can be manipulated using new line characters in the filename parameter. This can result in data being stealthily inserted, replaced or corrupted inside a file during the decoding process. Additionally the decode function can also be used to create new files in the same directory or system wide if direct access to the uu encoded file is possible.
The uu encoded file format is shown below:
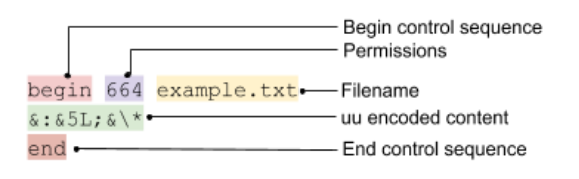
The vulnerabilities exist because the UU encoding format contains the filename and the python functions that create it do not prevent the filename from containing newline characters. This allows the filename to overflow into the uu encoded content area. We can insert valid uu encoded data, invalid data, or an end control sequence, this allows 4 slightly different attacks to occur. An additional attack can occur on the uu.decode method where the filename in the uu encoded file is used directly to create a file. These attacks are described in the examples below:
Attack Types
| Attack Type | Filename | Description |
|---|---|---|
| NULL | test\nend\n | File contents will be replaced with 0 bytes |
| CORRUPT | test\nabc | Decoding will fail due to invalid uu encoded char |
| INSERT | test\n&:&5L;&*\n | ‘hello’ will be inserted before the original file contents |
| REPLACE | test\n&:&5L;&*\nend\n | ‘hello’ will be replace the original file contents |
| FILE WRITE [1] | example.py\n | example.py will be created inside the current directory with the original file contents. This attack can also be used in combination with the INSERT / REPLACE / NULL attack. |
- NULL - Content can be dropped causing unintended paths and potentially denial of serviceor data loss.
- CORRUPTION - Using characters that are invalid in uu encoding such as lowercase a-z will cause the decoding process to fail.
- INSERT - Data can be stealthily inserted, potentially bypassing checks that have been performed to sanitize the data content.
- REPLACE - Data can be replaced stealthily, potentially bypassing checks that have been performed to sanitize the data content.
- FILE WRITE - This attack can bypass file extension checks that may occur on the filename. For example, a script may check that a file ends in .txt, however we could use a filename such as:
mallicious.py\n&:&5L;&\*\nend\ninnocent.txtthat would pass this test and still create an attack.py file upon decoding.
Functions Affected
The following functions are directly affected by this vulnerability:
- uu.py -
encode- Filename parameters passed unsanitized as filename in encoded output file (name defines filename, otherwise in_file is used) - uu.py -
decode- If out_file is not provided the filename in the encoded file is used directly to create the file which can cause an arbitrary non-overwriting file write from untrusted input. Note: this is limited to the current directory when using one of the filename attacks described above. However, if an attacker can write forward slashes into the uu file it can target the entire file system. - uu_codec.py -
uu_encode- Filename parameter passed unsanitized as filename in encoded output file
This also vulnerability also affects functions & methods that are built upon these ones such as:
codecs.open(filename, "w", "uu”)Mimetools.pypython -m uu -d
Proof of Concept
A short script has been created to demonstrate how to create malicious uu filenames, a snippet is shown below:
#!/usr/bin/python3.7
import codecs
maxFilenameLength=255
controlEnd='\nend\n'
# Generate uu encoded filename part
def generateUUEncodePart(data):
uuData = codecs.encode(data, 'uu')
uuData = uuData.replace(b"\n \nend\n", b"")
uuData = uuData.replace(b"begin 666 <data>\n", b"")
return uuData.decode("utf-8")
def attackNull(prefix='test', suffix='.txt'):
"""
NULL Attack
resulting file will be empty
"""
return prefix + controlEnd + suffix
def attackCorrupt(prefix='test', suffix='.txt'):
"""
CORRUPT Attack
this will raise an exception in decoding process
"""
return prefix + '\n' + 'a' + controlEnd + suffix
def attackInsert(prefix='test', data=b'this will appear'):
"""
INSERT Attack
data will be inserted at the top of file followed by original data
Suffix cannot be used in this case
"""
return prefix + '\n' + generateUUEncodePart(data) + '\n'
def attackReplace(prefix='test', suffix='.txt', data=b'this will appear'):
"""
REPLACE Attack
data will replace the original data
"""
return prefix + '\n' + generateUUEncodePart(data) + controlEnd + suffix
Disclosure & Fixes
The dicloure process was easy and didn’t take very long. I was communicating directly with Guido van Rossum, and I had no idea at the time that he was the inventor of Python.
I submitted an issue and a pull request with a fix to the affected functions that sanitizes the filename parameter to prevent this vulnerability.