REGEXSS: How .* Turned Into over $6k in Bounties
Overly-greedy regex replacements can break HTML sanitisation and lead to XSS. I’ve already pulled in over $6k from this bug class, and there are plenty more out there. Live demo included so you can have a play at exploiting it!


Intro
When you think of sources of Cross-Site Scripting (XSS) vulnerabilities, regex probably wouldn’t be one of the more obvious things that springs to mind, but a couple of weeks ago I teased that I’d hit something fun:
Last week I found two regex bugs using regex → unauth XSS → 2× $2k = $4k in bounties 🥳 If you’ve been putting it off, learn regex. Seriously. /regex+xss/$4k/ #BugBounty #BugBountyTips
I used regex to find a couple of regex vulnerabilities that lead to unauthenticated XSS and this post is the follow-up. I’ll break down what I meant by regex → XSS, how simple regex mistakes can lead to XSS vulnerabilities, and how one greedy quantifier turned into a $2k payout (twice).
We’ll look at:
- Classic regex slip-ups that cause bypasses
- REGEXSS - XSS born from regex mistakes
- A real-world example where cleaning HTML does the opposite
- Live Demo so you can have a go at exploiting it yourself!
If regex has always looked scary or over-complicated, hopefully this shows why it’s worth picking up. It pays off whether you’re coding or bug hunting.
What is REGEX?
Skip this section if you already know. Or don’t I’m not your social worker.
^(https?://)?([\da-z]+)\.([a-z]{2,6})([/\w.-]*)*/?$
At first glance, regex like this can look like someone accidentally fell asleep on their keyboard. That’s why I put off learning it for years, it just looked needlessly complex. But regex really isn’t as scary as it looks, and once you “get it”, it’s a superpower.
If you’ve been avoiding it, seriously: go learn it now. Not only will it make you a better developer and/or hacker, but you’ll also start spotting potential security issues.
There are some great tools and resources to make regex less intimidating:
- Regexr - shows what each part of the regex means and dynamically shows matches and grouping
- Regex Crossword - gamify your regex learning
- Magical Features of Regex in JavaScript - Some pure madness that is regex in JS (thanks busfactor).
REGEXSS
As a human (or even an AI trained on human input), it’s very easy to slip up when writing regex. A single character in the wrong place can completely change the meaning, and that could break your code or result in a vulnerability (if we’re lucky).
When you write regex you generally want it to Do as you mean, but regex engines are entirely literal and will only Do as you say. They’ll happily follow the pattern you wrote, not the pattern you intended.

Regex is doing as you say, not as you mean meme
There are plenty of examples of classic mistakes that are well known:
- Using
.instead of\.in a domain regex - suddenlytest.example.comalso matchestestXexample.com. Perfect allowlist bypass material. - Forgetting to anchor with
^or$- now your regex that was supposed to match only"admin"will happily match"notadminlol". - Writing
[A-z]thinking it’s just letters — but actually matching[ \ ] ^ _`too. Those sneaky ASCII symbols can give attackers wiggle room. - ReDoS: catastrophic backtracking in “complex” regexes can hang the regex engine and tie up CPU, causing a denial of service or other vulnerabilities.
- Remote code execution - Not seen much anymore but in older PHP versions it was possible to get code execution via
preg_replaceusing theemodifier.
But my newest favourite is overly greedy regex removals or replacements.
Greedy quantifiers like .*, .+, or even character sets like [^"]+ or [^"]* will happily eat as much as they can. That’s fine if you’re just matching pure text, but when used in a HTML context they can often grab more than intended by the author (matching across attribute and element boundaries). This is where the idea of REGEXSS comes in: cross-site scripting (XSS) that sneaks in through overly greedy regex. Gobble gobble.

Gobble gobble meme
That’s exactly what happened in the vulnerabilities I’ll walk through next: a single greedy regex intended to “clean” HTML instead created the perfect opportunity for an unauthenticated XSS.
The premise for this type of vulnerability is a regex removal or replacement acting on an HTML attribute, but written with a greedy quantifier between quotes (single, double or mixed). That means instead of neatly replacing or removing just the intended value, the regex can gobble up more than expected.
And that’s where things get interesting. With a little creativity, we can turn this overreach into something “fun”. Imagine the following regex is used to remove data from user-controlled but sanitised HTML content:
attribute=".*?"
.→ matches any single character (except line breaks).*→ means “zero or more of the preceding thing.”- Together
.*means “as many characters as possible.” - The trailing
?switches the.*from greedy to lazy matching, so it stops at next"it finds rather than running all the way to the last one. So instead of gobbling up multiple attributes, it matches only the intended value up to the next quote.
This is designed to remove any HTML attributes (named attribute) from any HTML tags inside $content. This works great and does exactly what the developer intended in a majority of cases. For example: the following HTML
<a href="test" attribute="value">test</a>
Would become:
<a href="test">test</a>
However, as an attacker there are a few tricks we can do:
Shifting the starting point - We can craft an attribute so the regex begins matching inside its value. This tricks the regex into spanning attributes it was never meant to touch. This will end the match at the next quote, which is usually at the start of the next attribute value.
<!-- Before: --> <a href="attribute=" title="javascript:alert('uhoh')">test</a> <!-- After: --> <a href="javascript:alert('uhoh')">test</a>Shift the ending point - Building on this we can force the regex to start inside one attribute value but use the mixing of single and double quotes to end the the regex match later in the attribute value.
<!-- Before: --> <a title='attribute="' href="new title' new-attribute='value'">test</a> <!-- After: --> <a title='new title' new-attribute='value'">test</a>Match across elements - We can advance on this and match across elements and content e.g.
<a title='attribute="' >"injection</a>. This can get around some limitations as single and double quotes are less likely to be encoded inside content, however, when matching across content, it will mean you are likely to leave dangling markup and break the HTML, which may or may not be acceptable for your use case.Across Elements:
<!-- Before: --> <a title='attribute="'><b id="' new-attribute='value'">Test</b></a> <!-- After: --> <a title='' new-attribute='value'">Test</b></a>Across Content:
<!-- Before: --> <div><img src='attribute="'>"x' onerror="alert(1)" </div> <!-- After: --> <div><img src='x' onerror="alert(1)" </div>
Where you’ll see this
This pattern is especially common in PHP and WordPress (thanks to widespread use of preg_replace), but you’ll also find it wherever people use regex-based sanitisation or ad-hoc replace logic, such as older CMSs, server-side template code, frontend filters and lightweight toolkits. In short: any codebase that prefers quick regex fixes over a proper HTML parser is a good hunting ground.
Requirements
Full exploitation requires that:
- the regex runs after any sanitization has occurred (Hint: regex can also be used to find instances of these vulnerable replacements).
- mixing of single and double quotes around HTML attributes is allowed.
Note: if quotes are always normalised (for example DOMPurify replaces single quotes to double quotes around attribute values) XSS becomes harder but not impossible. Normalisation blocks the easiest regexss payloads that rely on mixed quotes, but you can still end up injecting into restricted attributes. For example placing javascript:alert(document.cookie) into an href so that we can execute XSS on a click.
A Realistic Example
The code here will be shown in PHP, but pretty much all languages have a similar regex replacement function built-in (e.g. in JavaScript it would be string.replace). So let’s say you have an overly greedy regex replacement like the following:
$content = preg_replace('/data-target=".*?"/', '', $content);
This is designed to remove any HTML data-target HTML attributes from any HTML tags inside $content. This works great and does exactly what the developer intended in a majority of cases. However, we can create a totally valid HTML payload like the following:
<a href='https://sec.stealthcopter.com/regexss?data-target="'
title="' onfocus=alert(1) onfocus=1 tabindex=1 x=">regexss</a>
Which after this regex removal would drop the data-target="' title=", causing an attribute value to escape its context and be promoted to an attribute or set of attributes:
<a href='https://sec.stealthcopter.com/regexss?'
onfocus=alert(1) onfocus=1 tabindex=1 x=">regexss</a>
Which would execute the JavaScript in onfocus, via a classic XSS payload. So this would be an XSS via attribute injection caused by an REGEXSS vulnerable expression. :

Protection
This vulnerability class is sneaky because it’s so easy to make the mistake and hard to spot. I think it would be difficult for it to be detected by any static analysers or similar security tooling, it also passes the sniff test when using standard XSS payloads. Regex just can’t understand HTML context, it treats everything as plain text, so it’s a brittle choice for editing or sanitising markup. That said, regex is fast and familiar, so developers will often use it anyway. When you need to modify or clean HTML, use a proper parser (DOMDocument, DOMParser, or similar) so you operate on nodes and attributes rather than raw strings; parsers know the structure of HTML and avoid the class of breakage that leads to regexss.
Case Study: Schema & Structured Data for WP & AMP - Unauthenticated Stored-XSS
Here’s a real-world case I reported:
This WordPress plugin was one of two plugins I found with a flawed regex replacement that applied to comments from unauthenticated users, allowing for unauthenticated XSS. This was assigned CVE-2025-9512 and you can see the full Proof-of-Concept on wpscan. But basically it was a super simple regex replacement:
$content = preg_replace('/itemprop\=\"(.*?)\"/', "", $content);
So we could post a comment like this (no login required):
Hello this is a totally normal comment. Check out this cool website:
<a href='itemprop="' title="' tabindex=1 autofocus=1 onfocus=alert(1)//">stealthcopter</a>
Which after the preg_replace would become the following:
Hello this is a totally normal comment. Check out this cool website:
<a href='' tabindex=1 autofocus=1 onfocus=alert(1)//">stealthcopter</a>
We end up with slightly malformed HTML, but it’s still good enough to trigger the JavaScript payload.
Remediation
The fix for this vulnerability was to switch from regex to a proper HTML tag processor. Because the processor understands HTML context, an attacker can’t escape an attribute just by juggling quotes. Conveniently, WordPress has one built in. With WP_HTML_Tag_Processor they could strip the unwanted attributes in just a few easy to comprehend lines:
// WP_HTML_Tag_Processor class works on wordpress grater than wordpress 6.2
if ( class_exists( 'WP_HTML_Tag_Processor' ) ) {
$processor = new WP_HTML_Tag_Processor( $content );
while ( $processor->next_tag() ) {
$processor->remove_attribute( 'itemscope' );
$processor->remove_attribute( 'itemtype' );
$processor->remove_attribute( 'itemprop' );
This eliminates the vulnerability, but it also replaces ~50 lines of brittle regex they had with a handful of clear, maintainable code.
Live Demo
I built a small interactive demo page so you can try exploiting this vulnerability yourself. All the regexes in these challenges are based on real vulnerabilities I found in the wild. The demo lets you enter HTML, run a naive sanitiser (based on KSES) + a deliberately greedy regex, and see the sanitized HTML, the post-regex result, and the resulting HTML.
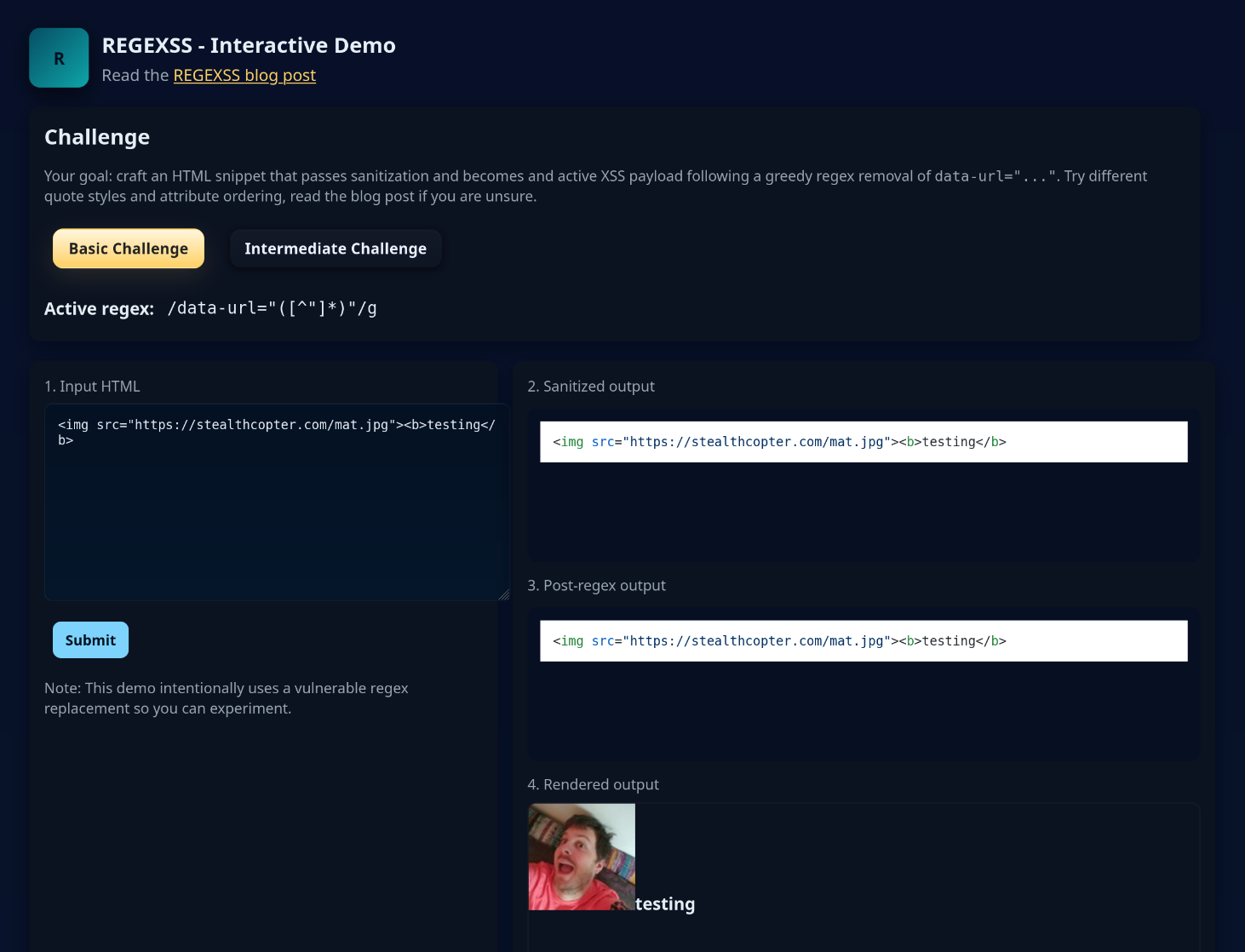
Screenshot of the demo page
AI: Accelerated Mistakes
If you ask an LLM for a sanitization function using regex, it will most likely do the right thing and highlight the dangers of using a pure regex solution, before piping out something that can be trivially exploitable using traditional or regexss techniques:
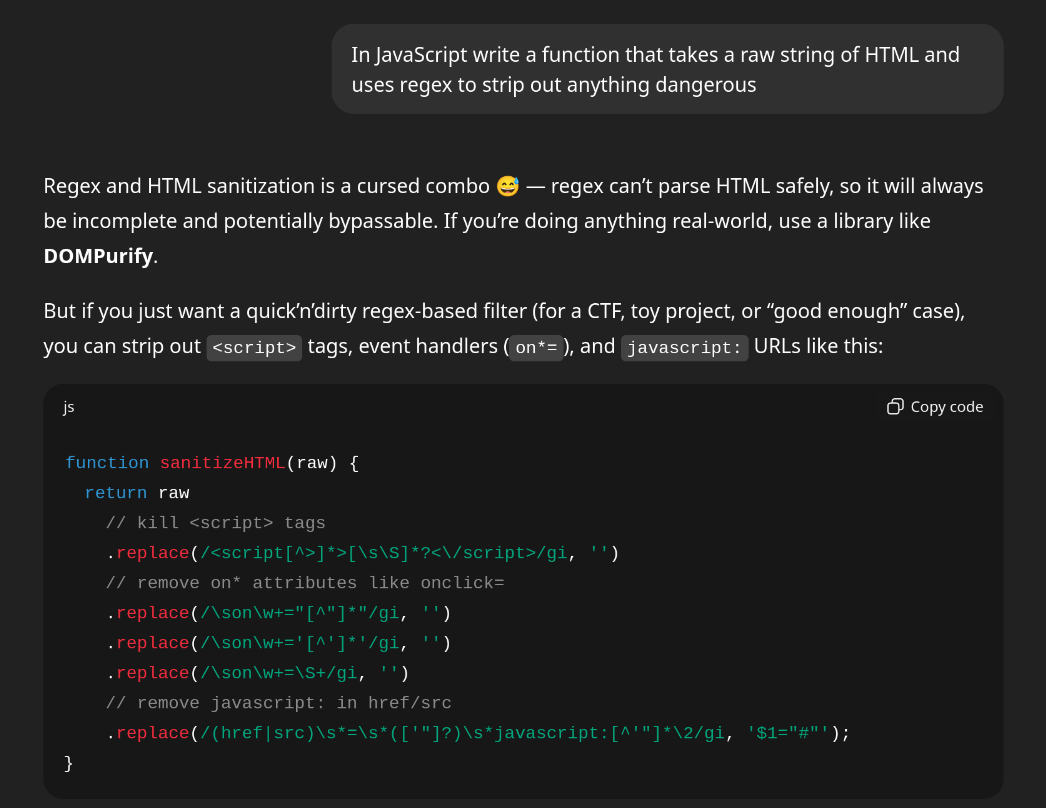
Example of an LLM-generated regex function conversation
However, the trouble starts when the LLM is given a partial implementation or used as an IDE autocomplete. In that scenario the model is far more likely to finish the function with a regex-based “quick fix” and skip the warning. The result looks plausible to a developer and is trivially bypassable using simple techniques such as regexss. As vibe coding and other LLM assisted code generation grows, these kinds of insecure regexes will likely become more frequent, especially given how difficult they are to automatically detect using traditional tooling.
Conclusion
Hope you’ve enjoyed this little adventure into small regex mistakes. So far it’s netted me just over $6k in bounties, with a few more still in triage. There are plenty more regex slip-ups out there waiting to be found. Let me know if you’ve found or find anything similar!